
There is now a widespread concern that the algorithms deployed to set prices, may `learn’ to collude and set prices above what one might consider to be the competitive level. Indeed, the FTC recently filed a brief against Yardi systems arguing such a possibility. For a summary of the FTCs position, see here.
While the concern is recent, interest in the possibility is not new. Among the earliest papers I am aware of is Kephart, Greenwald and Hansen (2000). In fact Kephart and Greenwald wrote more than one paper on the topic. They simulated different kinds of simple pricing algorithms (which they called pricebots) and demonstrated that it was possible, in the simulations, for supra-competitive prices to emerge. They also considered the possibility of consumers employing algorithms (which they called shopbots) to comparison shop. In their simulations they pitted one against the other. A cursory review of some recent papers suggests that this early work has been forgotten. See, for example, this recent paper in the AER.
Another paper that is often overlooked is Cooper et. al. (2015) In this paper, the authors consider two rival firms selling imperfect substitutes who in each period simultaneously set prices. Neither firm is aware of the underlying demand for their offering as a function of own and rival price. Each firm looks at the history of price-demand pairs observed so far to estimate a demand curve and then use it to myopically choose a price. They consider two scenarios. One where each firm employs a simple regression model: demand against own price only and each period pick a price that maximizes profit with respect to the estimated demand curve. In the second, each firm regresses own demand against own and rival price and then computes an equilibrium price. They demonstrate that in the first scenario, prices converge to a supra competitive level. In the second scenario, prices converge to the Nash equilibrium outcome which will be lower. Thus, employing less sophisticated algorithms results in higher prices! At first glance this seems surprising until one interprets an algorithm as a form of commitment and the `simpler’ model allows its user to commit to be less responsive to prices. See Hansen et al (2021) for a more general version of this.
Recent work tries to demonstrate empirically, the possibility of algorithmic collusion (see Assad et al (2024)) or show analytically (or experimentally) that pricing algorithms that are reminiscent of those used in practice will produce collusive outcomes (see, for example, Klein (2021) and Banchio and Mantegazza (2022)) Unsurprisingly, there are a flood of papers by legal scholars on the subject. I will not discuss as them as they confirm the assertion that while everything has been said, it has not yet been said by lawyers (Andre Gide might ascribe to this to the fact that none were listening).
Now, I turn to aspects of algorithmic collusion that have not been discussed very much. The first is that rivals employ the same software to set prices. As the FTC asserts agreeing to use an algorithm is an agreement. The idea is an old one it appears in Schelling’s Strategy of Conflict. Players in a game can benefit by delegating their choices to a third party. In this case, rivals delegate pricing decisions to a software vendor. Thus, the algorithm and the army of data scientists and software engineers employed by the vendor are merely window dressing. The vendor simply recommends the monopoly price to each firm and taking a siesta. This does not eliminate competition but shifts it to a dimension other than price. The price determines what a consumer will pay but not who they buy from. One saw this in the US during WW2 with wage controls. When airfares were regulated, Borenstein and Rose observe that competition shifted to schedule and service. Whether this is good or bad needs to be assessed. At least in the airline case, one person remembers those days with fondness. He is, of course, a lawyer.
What if the software vendor has control of `quantity’ but not price. One setting where this might be a possibility is in AI enabled recruiting. Consider a company like HireVu that recommends candidates to firms to fill vacancies. Suppose also that they are dominant within this industry. If a candidate were an excellent fit for many of its clients, is it in their interest to recommend that candidate to all the relevant clients? I argue, no. There is nothing to be gained from recommending an excellent candidate who is unlikely to accept an offer (because they have many offers) or whose wage will be high (because many firms are bidding for them). If HIreVu, for example, wishes to keep its clients, I conjecture that they should ration the candidates among their clients. This keeps wages low and yield for the client high. Thus, algorithmic quantity fixing could be just as much of a problem and may be more so because it would be harder to detect.
Next, suppose firms employ different pricing algorithms. Should we be concerned with them, the algorithms, learning to collude? The analytical and simulation results to date involve competition between the same algorithms. Thus, some coordination is built into the analysis. There is nothing that requires that firms use the same algorithm or different variants from the same class. Furthermore, if I knew what algorithm you were using would I want to employ the same algorithm? We already know the answer to this is `no’. There is a well known result, folklore now (for an explicit statement see Collina et al (2024)), that in Cournot competition, if my rival is using a no-regret learning algorithm (which has good guarantees when used in isolation) my best response is to pick the Stackleberg quantity repeatedly (actually, depending on the no-regret variant used one can do better). If your algorithm learns, that gives me an opportunity to teach it! Thus, it is not enough to know if a given profile of pricing algorithms will learn the collusive outcome. We need to know if firms will select such a profile of algorithms.
Lastly, even if it were the case that independent algorithms can sustain a collusive outcome, is regulation the necessary response. Consumers, also, can employ algorithms. Kephart and Greenwald called them shopbots. Michael Wellman and others were already speculating about them in 2000. Ichihashi and Smolin (2023) propose the question of how to design an optimal (for the consumer) shopbot and answer it in a simplified setting.
 . If a firm hires the worker for a wage of
. If a firm hires the worker for a wage of 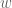 they earn a profit of
they earn a profit of  . Neither firm knows the worker’s type, but each receives a conditionally independent noisy signal of their type. We can think of the signal as being delivered by some mythical algorithm. Conditional independence is to be interpreted as the firms using different algorithms. Upon receiving their respective signals, each firm submits to the worker a take-it-or leave-it wage offer. The worker will select the firm that offers the highest wage. What’s just been described is a sealed bid first price auction in a common values setting. In equilibrium each firm will submit a wage that is below their estimate of worker productivity conditional on their signal because of the winner’s curse effect. On the other hand, suppose both firms use the same algorithm to estimate worker productivity that is error free, i.e., they receive perfect information about the worker’s productivity. Now, we have Bertrand competition and each firm offers a wage of $\latex t$. In this toy model, algorithmic monoculture does not affect efficiency, but it does affect the distribution of surplus. In particular, the worker benefits from homogenization! For a privacy slant with the same set up see
. Neither firm knows the worker’s type, but each receives a conditionally independent noisy signal of their type. We can think of the signal as being delivered by some mythical algorithm. Conditional independence is to be interpreted as the firms using different algorithms. Upon receiving their respective signals, each firm submits to the worker a take-it-or leave-it wage offer. The worker will select the firm that offers the highest wage. What’s just been described is a sealed bid first price auction in a common values setting. In equilibrium each firm will submit a wage that is below their estimate of worker productivity conditional on their signal because of the winner’s curse effect. On the other hand, suppose both firms use the same algorithm to estimate worker productivity that is error free, i.e., they receive perfect information about the worker’s productivity. Now, we have Bertrand competition and each firm offers a wage of $\latex t$. In this toy model, algorithmic monoculture does not affect efficiency, but it does affect the distribution of surplus. In particular, the worker benefits from homogenization! For a privacy slant with the same set up see 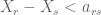 . Inequalities of this form arise in a variety of places. They can be interpreted as the dual to the problem of finding a shortest path in a network. Their feasibility is related to Rockafellar’s cyclic monotonicity condition. They arise in revealed preference and mechanism design. All the results one needs for the various applications appear in that paper.
. Inequalities of this form arise in a variety of places. They can be interpreted as the dual to the problem of finding a shortest path in a network. Their feasibility is related to Rockafellar’s cyclic monotonicity condition. They arise in revealed preference and mechanism design. All the results one needs for the various applications appear in that paper. be the set of possible states and
be the set of possible states and 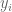 be the output in state
be the output in state 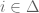 . Without loss we may assume that
. Without loss we may assume that  . An action for an agent is a pair
. An action for an agent is a pair 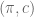 where
where 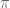 is a probability distribution over
is a probability distribution over  a cost. Denote by
a cost. Denote by 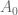 the set of known actions of which a typical element is written as
the set of known actions of which a typical element is written as 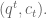
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) represents the share of output that goes to the agent. Actually, the requirement that
represents the share of output that goes to the agent. Actually, the requirement that 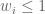 is not needed. The expected payoff to the agent under contract
is not needed. The expected payoff to the agent under contract 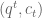 is
is 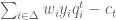 . Let
. Let 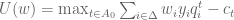 . Thus,
. Thus, 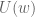 represents the agent’s expected payoff from choosing an action in
represents the agent’s expected payoff from choosing an action in 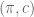 to offer the agent so as to minimize the principal’s payoff. Nature’s choice can be formulated as the following linear program:
to offer the agent so as to minimize the principal’s payoff. Nature’s choice can be formulated as the following linear program: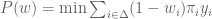
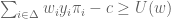
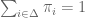
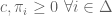
![\alpha \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) in each state of the world to the agent. Let
in each state of the world to the agent. Let 
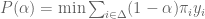
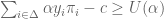
 is called admissible if
is called admissible if 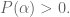
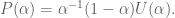
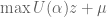
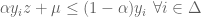
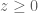
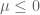 .
. must satisfy one of the following:
must satisfy one of the following:

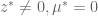
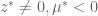
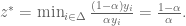
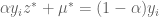
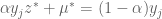
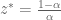 and therefore,
and therefore, 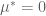 , which puts us back in #3. QED
, which puts us back in #3. QED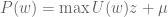
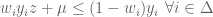
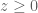
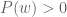 and
and 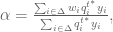 then,
then,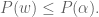
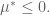
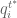 and add them up. This yields the following:
and add them up. This yields the following: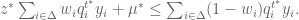
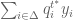 :
:![\alpha z^* + [\sum_{i \in \Delta}q_i^{t^*}y_i]^{-1}\mu^* \leq (1-\alpha)](https://s0.wp.com/latex.php?latex=%5Calpha+z%5E%2A+%2B+%5B%5Csum_%7Bi+%5Cin+%5CDelta%7Dq_i%5E%7Bt%5E%2A%7Dy_i%5D%5E%7B-1%7D%5Cmu%5E%2A+%5Cleq+%281-%5Calpha%29&bg=ffffff&fg=545454&s=0&c=20201002)
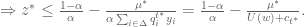
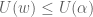 , it follows that
, it follows that![P(w) \leq [\frac{1-\alpha}{\alpha} - \frac{\mu^*}{U(w) + c_{t^*}}]U(w) + \mu^*](https://s0.wp.com/latex.php?latex=P%28w%29+%5Cleq+%5B%5Cfrac%7B1-%5Calpha%7D%7B%5Calpha%7D+-+%5Cfrac%7B%5Cmu%5E%2A%7D%7BU%28w%29+%2B+c_%7Bt%5E%2A%7D%7D%5DU%28w%29+%2B+%5Cmu%5E%2A&bg=ffffff&fg=545454&s=0&c=20201002)
 QED
QED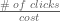 . Hence, the ROI is the inverse of the cost per click.
. Hence, the ROI is the inverse of the cost per click. . Then, my ROI target, says that the platform must deliver
. Then, my ROI target, says that the platform must deliver 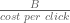 clicks. For example, at a budget of $100 and an ROI target of 2, I am telling the platform that I will give them $100 in return for 200 clicks. Now, the platform, has access not to a finite number of clicks but a flow. They can, given time, satisfy every bid. In short, the platform will get your $100. The only issue is when. The automated auction is merely an elaborate device for determining the rate at which different bidders receive a click. One can think of far simpler procedures to do this. For example, round robin or deplete budgets at a uniform rate.
clicks. For example, at a budget of $100 and an ROI target of 2, I am telling the platform that I will give them $100 in return for 200 clicks. Now, the platform, has access not to a finite number of clicks but a flow. They can, given time, satisfy every bid. In short, the platform will get your $100. The only issue is when. The automated auction is merely an elaborate device for determining the rate at which different bidders receive a click. One can think of far simpler procedures to do this. For example, round robin or deplete budgets at a uniform rate.
Recent Comments