
You are currently browsing the monthly archive for March 2016.
Platooning, driverless cars and ride hailing services have all been suggested as ways to reduce congestion. In this post I want to examine the use of coordination via ride hailing services as a way to reduce congestion. Assume that large numbers of riders decide to rely on ride hailing services. Because the services use Google Maps or Waze for route selection, it would be possible to coordinate their choices to reduce congestion.
To think thorough the implications of this, its useful to revisit an example of Arthur Pigou. There is a measure 1 of travelers all of whom wish to leave the same origin (


A central planner, say, Uber, interested in minimizing total travel time will route half of all travelers through the top and the remainder through the bottom. Total travel time will be 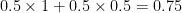

Now suppose, there are two competing ride hailing services. Assume fraction 
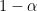
![{\alpha \in [1/3, 2/3]}](https://s0.wp.com/latex.php?latex=%7B%5Calpha+%5Cin+%5B1%2F3%2C+2%2F3%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
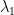
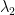
A straight forward calculation reveals that the only Nash equilibrium of the Uber vs. Lyft game is 
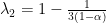
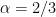
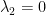
![\displaystyle 0.5 \times 1 + 0.5 \times [0.5 \times (2/3) + 1/3] = 5/6.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+0.5+%5Ctimes+1+%2B+0.5+%5Ctimes+%5B0.5+%5Ctimes+%282%2F3%29+%2B+1%2F3%5D+%3D+5%2F6.&bg=ffffff&fg=000000&s=0&c=20201002)
The travel time for a Lyft user will be
![\displaystyle [0.5 \times (2/3) + 1/3] = 2/3.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0.5+%5Ctimes+%282%2F3%29+%2B+1%2F3%5D+%3D+2%2F3.&bg=ffffff&fg=000000&s=0&c=20201002)
Total travel time will be 
Suppose we include prices and assume that travelers now evaluate a ride hailing service based on delivered price, that is price plus travel time. Thus, we are assuming that all travelers value time at $1 a unit of time. The volume of customers served by Uber and Lyft is no longer fixed and they will focus on minimizing average travel time per customer. A plausible guess is that there will be an equal price equilibrium where travelers divide evenly between the two services, i.e., 

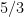

What this simple minded analysis highlights is that the benefits of coordination may be hard to achieve if travelers can opt out and drive themselves. To minimize congestion, the ride hailing services must limit traffic on the bottom path. This is the one that is congestible. However, doing so makes its attractive in terms of travel time encouraging travelers to opt out.
I am not the right person to write about Lloyd Shapley. I think I only saw him once, in the first stony brook conference I attended. He reminded me of Doc Brown from Back to The Future, but I am not really sure why. Here are links to posts in The Economist and NYT following his death.
Shapley got the Nobel in 2012 and according to Robert Aumann deserved to get it right with Nash. Shapley himself however was not completely on board: “I consider myself a mathematician and the award is for economics. I never, never in my life took a course in economics.” If you are wondering what he means by “a mathematician” read the following quote, from the last paragraph of his stable matching paper with David Gale
The argument is carried out not in mathematical symbols but in ordinary English; there are no obscure or technical terms. Knowledge of calculus is not presupposed. In fact, one hardly needs to know how to count. Yet any mathematician will immediately recognize the argument as mathematical…
What, then, to raise the old question once more, is mathematics? The answer, it appears, is that any argument which is carried out with sufficient precision is mathematical
In the paper Gale and Shapley considered a problem of matching (or assignment as they called it) of applicants to colleges, where each applicant has his own preference over colleges and each college has its preference over applicants. Moreover, each college has a quota. Here is the definition of stability, taken from the original paper
Definition: An assignment of applicants to colleges will be called unstable if there are two applicants 


According to the Gale-Shapley algorithm, applicants apply to colleges sequentially following their preferences. A college with quota 
One reason that the paper was so successful is that the Gale Shapley method is actually used in practice. (A famous example is the national resident program that assigns budding physicians to hospitals). From theoretical perspective my favorite follow-up is a paper of Dubins and Freedman “Machiavelli and the Gale-Shapley Algorithm” (1981): Suppose that some applicant, Machiavelli, decides to `cheat’ and apply to colleges in different order than his true ranking. Can Machiavelli improves his position in the assignment produced by the algorithm ? Dubins and Freedman prove that the answer to this question is no.
Shapley’s contribution to game theory is too vast to mention in a single post. Since I mainly want to say something about his mathematics let me mention Shapley-Folkman-Starr Lemma, a kind of discrete analogue of Lyapunov’s theorem on the range of non-atomic vector measures, and KKMS Lemma which I still don’t understand its meaning but it has something to do with fixed points and Yaron and I have used it in our paper about rental harmony.
I am going to talk in more details about stochasic games, introduced by Shapley in 1953, since this area has been flourishing recently with some really big developments. A (two-player, zero-sum) stochastic game is given by a finite set 

![{r:Z\times A\times B\rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Br%3AZ%5Ctimes+A%5Ctimes+B%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



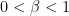

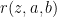
A major question, following a similar question in the single player setup, is the limit behavior of the value and the optimal strategies when players become more patient (i.e., 



Recent Comments