
You are currently browsing the tag archive for the ‘zero-sum games’ tag.
Peter Bickel taught me a nifty, little, literally, proof of the minimax theorem. Peter says it was inspired by his reading of David Blackwell‘s vector generalization of the same. Here goes.
Let 
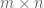


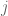
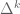
For each 






![C(q)= (-\infty, d(q)].](https://s0.wp.com/latex.php?latex=C%28q%29%3D+%28-%5Cinfty%2C+d%28q%29%5D.&bg=ffffff&fg=545454&s=0&c=20201002)
For any 


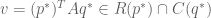
No Farkas or separating hyperplane. Now, minimax is equivalent to duality. So, one might wonder whether such a proof could be used to obtain the duality theorem of linear programming. Assuming that the primal and the dual had optimal solutions, yes. However, the case where one is infeasible or unbounded would cause this kind of proof to break.
PS: Then, Olivier Gossner pointed out that perhaps because I wanted to believe so much that it was true, that I had overlooked something. See the comments. He was right. I tried to make the proof work but could not. A proof of minimax that avoids Farkas and/or the separating hyperlane is not outlandish. There is Guillermo Owen’s proof, via induction, for example. By the way this was not the first such elementary proof. There was a flurry elementary proofs of the minimax in the 40s and 50s in response to a challenge of von Neumann. Indeed, Peck (1958) writes in the introduction to his paper:
“There are so many proofs of this theorem in the literature, that an excuse is necessary before exhibiting another. Such may be found by examining the proof given below for the following: it uses no matrices, almost no topology and makes little use of the geometry of convex sets; it applies equally well to the case where only one of the pure strategy spaces is finite; also there is no assumption that the payoff function is bounded.”
That an induction proof should exist is unsurprising given David Gale’s inductive proof of the Farkas lemma. In fact, Gale’s proof can be seen as an instantiation of Fourier’s method for solving linear programs, again, no Farkas or separating hyperplane.
I am not the right person to write about Lloyd Shapley. I think I only saw him once, in the first stony brook conference I attended. He reminded me of Doc Brown from Back to The Future, but I am not really sure why. Here are links to posts in The Economist and NYT following his death.
Shapley got the Nobel in 2012 and according to Robert Aumann deserved to get it right with Nash. Shapley himself however was not completely on board: “I consider myself a mathematician and the award is for economics. I never, never in my life took a course in economics.” If you are wondering what he means by “a mathematician” read the following quote, from the last paragraph of his stable matching paper with David Gale
The argument is carried out not in mathematical symbols but in ordinary English; there are no obscure or technical terms. Knowledge of calculus is not presupposed. In fact, one hardly needs to know how to count. Yet any mathematician will immediately recognize the argument as mathematical…
What, then, to raise the old question once more, is mathematics? The answer, it appears, is that any argument which is carried out with sufficient precision is mathematical
In the paper Gale and Shapley considered a problem of matching (or assignment as they called it) of applicants to colleges, where each applicant has his own preference over colleges and each college has its preference over applicants. Moreover, each college has a quota. Here is the definition of stability, taken from the original paper
Definition: An assignment of applicants to colleges will be called unstable if there are two applicants 



According to the Gale-Shapley algorithm, applicants apply to colleges sequentially following their preferences. A college with quota 
One reason that the paper was so successful is that the Gale Shapley method is actually used in practice. (A famous example is the national resident program that assigns budding physicians to hospitals). From theoretical perspective my favorite follow-up is a paper of Dubins and Freedman “Machiavelli and the Gale-Shapley Algorithm” (1981): Suppose that some applicant, Machiavelli, decides to `cheat’ and apply to colleges in different order than his true ranking. Can Machiavelli improves his position in the assignment produced by the algorithm ? Dubins and Freedman prove that the answer to this question is no.
Shapley’s contribution to game theory is too vast to mention in a single post. Since I mainly want to say something about his mathematics let me mention Shapley-Folkman-Starr Lemma, a kind of discrete analogue of Lyapunov’s theorem on the range of non-atomic vector measures, and KKMS Lemma which I still don’t understand its meaning but it has something to do with fixed points and Yaron and I have used it in our paper about rental harmony.
I am going to talk in more details about stochasic games, introduced by Shapley in 1953, since this area has been flourishing recently with some really big developments. A (two-player, zero-sum) stochastic game is given by a finite set 

![{r:Z\times A\times B\rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Br%3AZ%5Ctimes+A%5Ctimes+B%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



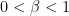

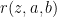
A major question, following a similar question in the single player setup, is the limit behavior of the value and the optimal strategies when players become more patient (i.e., 



Credit for the game that bears his name is due to to Borel. It appears in a 1921 paper in French. An English translation (by Leonard Savage) may be found in a 1953 Econometrica.

The first appearance in print of a version of the game with Colonel Blotto’s name attached is, I believe, in the The Weekend Puzzle Book by Caliban (June 1924). Caliban was the pen name of Hubert Phillips one time head of Economics at the University of Bristol and a puzzle contributor to The New Statesman.
Blotto itself is a slang word for inebriation. It does not, apparently, derive from the word `blot’, meaning to absorb liquid. One account credits a French manufacturer of delivery tricycles (Blotto Freres, see the picture) that were infamous for their instability. This inspired Laurel and Hardy to title one of their movies Blotto. In it they get blotto on cold tea, thinking it whiskey.
Over time, the Colonel has been promoted. In 2006 to General and to Field Marshall in 2011.
Department of self-promotion: sequential tests, Blackwell games and the axiom of determinacy.
Recap: At every day 
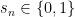

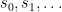
![{R\subseteq \bigl([0,1]\times\{0,1\}\bigr)^{\mathbb N}}](https://s0.wp.com/latex.php?latex=%7BR%5Csubseteq+%5Cbigl%28%5B0%2C1%5D%5Ctimes%5C%7B0%2C1%5C%7D%5Cbigr%29%5E%7B%5Cmathbb+N%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{f:\{0,1\}^{<{\mathbb N}}\rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5C%7B0%2C1%5C%7D%5E%7B%3C%7B%5Cmathbb+N%7D%7D%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
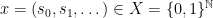




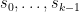
Let me remind you what I mean by `a test that does not reject the truth with probability 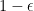
Definition 1 The test does not reject the truth with probabality
-valued stochastic process
one has


We are going to prove the following theorem:
Theorem 2 Consider a sequential test that does not reject the true expert with probability
there exists a
such that

So a charlatan, who doesn’t know anything about the true distribution of the process, can randomize a forecast according to 
— Discussion —
Before we delve into the proof of the theorem, a couple of words about where we are. Recall that a forecast 

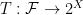
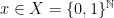

Sequential tests have the additional property that the test’s verdict depends only on predictions made by 
One situation in which sequential tests are the only available tests is when, instead of providing his entire forecast 
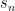

— Sketch of Proof —
We can transform the expert’s story to a two-player normal form zero-sum game as we did before: Nature chooses a realization 
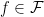

Unfortunately, this time we cannot use Fan’s Theorem since we made no topological assumption about the set 

- The game is played in stages
.
- At stage
simultaneously and independently.
- Nature does not monitor past actions of Expert.
- Expert monitors past actions
of Nature.
- At infinity, Expert pays Nature
Now I am going to assume that you are familiar with the concept of strategy in extensive form game, and are aware of Kuhn’s Theorem about the equivalence between behavioral strategies and mixtures of pure strategies (I will make implicit uses of both directions of Kuhn’s Theorem in what follows). We can then look at the normal form representation of this game, in which the players choose pure strategies. A moment’s thought will convince you that this is exactly the game from the previous paragraph: Nature’s set of pure strategies is 

Here is the game after the twist. I call this game 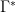
- The game is played in stages
- At stage
- Each player monitors past actions of the opponent.
- At infinity, Expert pays Nature
Now if you internalized the method of proving manipulability that I was advocating in the previous two episodes, you know what’s left to prove: that the maximin of
Here is the most important insight of the proof: The fact that an expert who knows the distribution of the process can somehow pass the test 
Let ![{g:\left([0,1]\times \{0,1\}\right)^{<{\mathbb N}}\rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bg%3A%5Cleft%28%5B0%2C1%5D%5Ctimes+%5C%7B0%2C1%5C%7D%5Cright%29%5E%7B%3C%7B%5Cmathbb+N%7D%7D%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
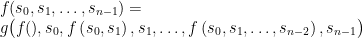
So the pure action taken by the Expert player at day 
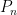
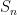
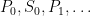
Now for the minor inaccuracy that I mentioned: For Martin’s Theorem we need the set of actions at every stage to be finite. We can handle this obstacle by restricting Expert’s action at every stage to a grid and applying the coupling argument.
— Non-Borel Tests —
What about pathological sequential tests that are given by a non-Borel set
If, on the other hand, you subscribe to the axiom of choice, then you have a non-manipulable test:
Theorem 3 There exists a sequential test with a non-Borel set

— Summary —
If you plan to remember one conclusion from my last three posts, I suggest you pick this: There exist non-manipulable tests, but they must rely on counter-factual predictions, or be extremely pathological.
Muchas gracias to everyone who read to this point. Did I mention that I have a paper about this stuff ?
I am visiting the rationality center in the Hebrew University, and I am presenting some papers from the expert testing literature. Here are the lecture notes for the first talk. If you read this and find typos please let me know. The next paragraph contains the background story, and can be safely skipped.
A self-proclaimed expert opens a shop with a sign at the door that says `Here you can buy probabilities’. So the expert is a kind of a fortune-teller, he provides a service, or a product, and the product that the expert provides is a real number: the probability of some event or more generally the distribution of some random variable. You can ask for the probability of rain tomorrow, give the expert some green papers with a picture of George Washington and receive in return a paper with a real number between 0 and 1. The testing literature asks whether you can, after the fact, check the quality of the product you got from the expert, i.e. whether the expert gave you the correct probability or whether he just emptied your pocket for a worthless number.
So, let 



— Manipulability —
I start with Sandroni’s paper (pdf). The following definition formalises the idea that the true expert is unlikely to fail the test
Definition 1 The test
for every
.
If a test does not reject the truth with probability
Theorem 2 (Sandroni (2003)) Let
such that
for every
So, a charlatan who knows nothing about how Nature chooses
For Sandroni’s Theorem we do not need to assume any structure on 

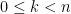

Proof: Let 

Consider the following two-player zero-sum game with the players called Nature and Expert. Nature is the maximizer with pure strategies set 


By von-Neumann’s Minimax Theorem the game admits a value 




Now let 

for every pure strategy

The argument in the proof of Sandroni’s Theorem captures the essence of all the manipulability theorems we will see. We define a zero-sum game between two players, Nature and Expert. The minimax theorem is the core of the proof: The fact that the maximin is smaller than
— Fan’s Theorem —
Here is the more general minimax theorem which we will use later: In a zero-sum game, if one of the players have a compact set of pure strategies, and the payoff to that player is u.s.c. in his own strategy then the game admits a value in mixed strategies.
Proposition 3 (Ky Fan)Consider a two-player zero-sum game in normal form with pure strategy sets
and payoff function
. If
is upper-semi continuous for every
and all suprema are attained.

The set 
— Non-manipulability —
Sandroni’s Theorem does not hold when
Example 1 Let
. Let
Then
there exists a realization


Not only the test is not manipulable, also for every 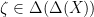
Proof: For every 



We first show that the test has small probability to reject a true expert. Indeed,

for every
Now let 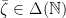

![\displaystyle \begin{array}{rcl} \lefteqn{\zeta\bigl(\{\mu\in\Delta(X)|x\in T(\mu)\}\bigr)=}\\&&\zeta\bigl(\{\mu\in\Delta(X)|x\geq t(\mu)\}\bigr)=\bar\zeta\left([0,x]\right)\geq 1-\epsilon.\end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Clefteqn%7B%5Czeta%5Cbigl%28%5C%7B%5Cmu%5Cin%5CDelta%28X%29%7Cx%5Cin+T%28%5Cmu%29%5C%7D%5Cbigr%29%3D%7D%5C%5C%26%26%5Czeta%5Cbigl%28%5C%7B%5Cmu%5Cin%5CDelta%28X%29%7Cx%5Cgeq+t%28%5Cmu%29%5C%7D%5Cbigr%29%3D%5Cbar%5Czeta%5Cleft%28%5B0%2Cx%5D%5Cright%29%5Cgeq+1-%5Cepsilon.%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
The first equality follows from the definition of 
— Sequential Tests —
So, Sandroni’s Theorem only holds for finite sets 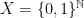

There is an almost equivalent representation of and element 





For every 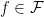

Definition 4 A test
implies
for every
and every realization
and
along
Equivalently, a sequential test is given by a subset ![{R\subseteq ([0,1]\times \{0,1\})^{\mathbb N}}](https://s0.wp.com/latex.php?latex=%7BR%5Csubseteq+%28%5B0%2C1%5D%5Ctimes+%5C%7B0%2C1%5C%7D%29%5E%7B%5Cmathbb+N%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


— Next Episode (Thursday 12:00) —
I will talk about Olszewski and Sandroni’s paper `The manipulability of future independent tests’ and my paper `Many inspections are manipulable’ . Main goal is to prove that sequential tests are always manipulable.
I wrote some time ago about Michael Rabin’s example of how a backward induction argument is killed when you require players’ plans to be computable. Since Rabin’s paper is not available online, I intended to post the proof at some point, but never actually got to do it. Richard Lipton’s post about Emil Post is a good inspiration to pay that debt since the concept of simple set, which was introduced by Post, has a role in Rabin’s example.
A set 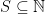

For Rabin’s purpose, what matters is that Post proved the existence of such a set. So Post provides us with a code of a computer program that enumerates over all the elements of
Now let 
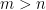
Does any of the players have a strategy that guarantee winning regardless of how the opponent play ? The answer to this question depends on which mathematical creature you use to model the intuitive notion of `strategy’.
If by a strategy you mean just a function from histories to current action then Bob has a winning strategy: for every 
But if you think of a strategy as a complete set of instructions, that is a plan or an algorithm that will tell you how to produce your next action given the past, then you want to model a strategy as a computable function. Now, for every computable function 


Since in the near future I will have to start advocating a computability argument, and since this position is somewhat in contrast to what was my view a couple of years ago when I first came across algorithmic game theory, I thought I should try to clarify my thoughts about the issue in a couple of posts.
The most beautiful example I know for the surprising outcomes we get when taking computability into account in game theory is Michael Rabin’s paper from 1957. Rabin considers a finite win-loss game with perfect information between two players, Alice and Bob. The game is played in three rounds, at each round a player announces a natural number (an action): First Alice announces 



Rabin gives an example for a game with the following propertie:
whether or not
- Bob has a winning strategy
: so that
for any
- Bob has no computable winning strategy: For every function
for Alice such that
.
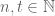
Feel the blow ? Bob finds himself in a strange predicament. On the one hand, after observing Alice’s action
(To be continued…)

Recent Comments