
You are currently browsing the tag archive for the ‘multiarmed bandit’ tag.
This post is only gonna make sense if you read my last-week post on Gittins Index
So, why does Gittins’ theorem hold for arms and not for projects ?
First, an example. Consider the following two projects A and B. The first period you work on A you have to choose an action Up or Down. Future rewards from working on project A depend on your first action. The (deterministic) rewards sequence is
A: 8, 0, 0, 0, … if you played Up; and 5, 5, 5, 5, … if you played Down.
Project B gives the deterministic rewards sequence
B: 7, 0, 0,…
If your discount factor is high (meaning you are sufficiently patient) then your best strategy is to start with project B, get 7 and then switch to project A, play Down and get 5 every period.
Suppose now that there is an additional project, project C which gives the deterministic payoff sequence
C: 6,6,6,….
Your optimal strategy now is to start with A, play Up, and then switch to C.
This is a violation of Independence of Irrelevant Alternatives: when only A and B are available you first choose B. When C becomes available you suddenly choose A. The example shows that Gittins’ index theorem does not hold for projects.
What goes wrong in the proof ? We can still define the “fair charges” and the “prevailing charges” as in the multi-armed proof. For example, the fair charge for project A is 8: If the casino charges a smaller amount you will pay once, play Up, and go home, and the casino will lose money.
The point where the proof breaks down is step 5. It is not true that Gittins’ strategy maximizes the payments to the casino. The key difference is that in the multi-project case the sequence of prevailing charges of each bandit depends on your strategy. In contrast, in the multi-arm case, your strategy only determines which charge you will play when, but the charges themselves are independent of your strategy. Since the discounts sequence 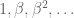
After presenting Richard Weber’s remarkable proof of Gittins’ index theorem in my dynamic optimization class, I claimed that the best way to make sure that you understand a proof is to identify where the assumptions of the theorem are used. Here is the proof again, slightly modified from Weber’s paper, followed by the question I gave in class.
First, an arm or a bandit process is given by a countable state space 

![r:S\rightarrow [0,1]](https://s0.wp.com/latex.php?latex=r%3AS%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

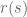
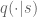
In the multi-armed bandit problem, at every period you choose an arm to play. The states of the arms you didn’t choose remain fixed. Your goal is to maximize expected total discounted rewards. Gittins’ theorem says that for each arm there exists a function ![\gamma:S\rightarrow [0,1]](https://s0.wp.com/latex.php?latex=%5Cgamma%3AS%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)
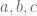


The proof proceeds in several steps:
- Define the Gittins Index at state
such that, if the casino charges
- Assume that you enter a casino with a single arm at some state
.
- Continuing with a single arm, assume now that the casino announces a new policy that at every period, if the arm reaches a state with GI that is strictly smaller than the GI of all previous states, then the charge for playing the arm drops to the new GI. We call these new (random) charges the prevailing charges. Again, the casino will always get a nonnegative net expected payoff, and if you play optimally then the net expected payoff is zero. Here, playing optimally means that you either not play at all or start playing and continue to play forever. You can quit or take a bathroom break only at periods in which the prevailing charge equals the GI of the current state.
- Consider now the multi-arms problem, and assume again that in order to play an arm you have to pay its current prevailing charge as defined in step 3. Then again, regardless of how you play, the Casino will get a nonnegative net payoff (since by step 3 this is the case for every arm separately), and you can still get an expected net payoff
if you play optimally. Playing optimally means that you either not play or start playing. If you start playing you can quit, take a break, or switch to another arm only in periods in which the prevailing charge of the arm you are currently playing equals the GI of its current state.
- Forget for a moment about your profits and assume that what you care about is maximizing payments to the casino (I don’t mean net payoff, I mean just the charges that the casino receives from your playing). Since the sequence of prevailing charges of every arm is decreasing, and since the discount factor makes the casino like higher payments early, the Gittins strategy — the one in which you play at each period the arm with highest current GI, which by definition of the prevailing charge is also the arm with highest current prevailing charge — is the one that maximizes the Casino’s payments. In fact, this would be the case even if you knew the realization of the charges sequence in advance.
- The Gittins strategy is one of the optimal strategies from step 4. Therefore, its net expected payoff is
- Therefore, for every strategy
,
Rewards fromCharges from
(First inequality is step 4 and second is step 5)
And Charges from Gittins strategy = Rewards from Gittins Strategy
(step 6) - Therefore, the Gittins strategy gives the optimal possible total rewards.
That’s it.
Now, here is the question. Suppose that instead of arms we would have dynamic optimization problems, each given by a state space, an action space, a transition function, and a payoff function. Let’s call them projects. The difference between a project and an arm is that when you decide to work on a project you also decide which action to take, and the current reward and next state depend on the current state and on your action. Now read again the proof with projects in mind. Every time I said “play arm 
Here is the question from Ross’ book that I posted last week
Question 1 We have two coins, a red one and a green one. When flipped, one lands heads with probability
and the other with probability
. Assume that
. We do not know which coin is the
to the red coin being the
. Find the optimal policy.
This is a dynamic programming problem where the state is the belief that the red coin is
In the classical bandit problem there are 

![{\theta_i\in\Delta([0,1])}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta_i%5Cin%5CDelta%28%5B0%2C1%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
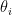
![{\mu_i\in \Delta(\Delta([0,1]))}](https://s0.wp.com/latex.php?latex=%7B%5Cmu_i%5Cin+%5CDelta%28%5CDelta%28%5B0%2C1%5D%29%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)



The independence assumption means that we only learn about the distribution of the arm we are using. This assumption is not satisfied in the red coin green coin problem: If we toss the red coin and get heads then the probability that the green coin is
Here is my solution. Call the problem I started with `the difficult problem’ and consider a variant which I call `the easy problem’. Let 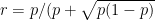




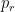
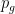
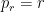
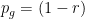
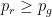

Now here comes the trick. Consider a general strategy 


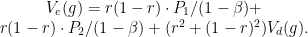
Why is that ? in the easy problem there is a probability 
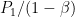



So, the payoff in the easy problem is a linear function of the payoff in the difficult problem. Therefore the optimal strategy in the difficult problem is the same as the optimal strategy in the easy problem. In particular, we just proved that, for every
See why I said my solution is tricky and specific ? it relies on the fact that there are only two arms (the fact that the arms are coins is not important). Here is a problem whose solution I don’t know:
Question 2 Let
. We are given
possibilities equally likely. Each period we have to toss a coin and we get payoff
for Heads. What is the optimal strategy ?

Recent Comments