
At a recent Algorithmic Fairness meeting, there was some discussion of algorithmic homogenization. The concern, as expressed, for example in Kleinberg and Raghavan (2021) is that
“the quality of decisions may decrease when multiple firms use the same algorithm. Thus, the introduction of a more accurate algorithm may decrease social welfare—a kind of “Braess’ paradox” for algorithmic decision-making”.
Now, no new model is needed to exhibit such a paradox for algorithmic decision making. The prisoner’s dilemma will do the job for us. Consider the instance of the dilemma in the table below.
| C | D | |
| C | (1,1) | (-1,5) |
| D | (5,-1) | (0,0) |
Here are two algorithms that our players can choose from to play the game. The first is a silly algorithm. It selects a strategy uniformly at random from among those available. The second is a `better’ algorithm. Its selects a strategy uniformly at random among those are rationalizable (meaning they are a best response to some mixed strategy of the opponent). Why is the second better? Holding the strategy of the opponent fixed, the second will deliver a higher expected payoff than the first. This is because strategy D, defect, is the only rationalizable strategy in the prisoner’s dilemma.
If both players use the inferior algorithm, total expected payoff will be 5/4. If both players use the better algorithm, total expected payoff will be 0. Thus social welfare is lower when both players switch to the better algorithm. Why doesn’t each player stick with the silly algorithm? If I know my rival is playing the silly algorithm, I am better off from switching to the better algorithm.
While this example makes the point, it does so unconvincingly because it is not tied to a compelling context. KR(2021) does not share this feature because it relies on algorithmic hiring as motivation. There are two firms competing to hire individuals and they may deploy algorithms to screen candidates. Unlike the example above, the algorithm does not choose each firm’s actions but provides information only about candidate quality. In other words, the algorithm makes predictions not decisions.
The idea that better information in a competitive context can make the players worse off is not a new one. Nevertheless, it is always useful to understand the precise mechanism by which this plays out in different contexts. The same is true in this case and I direct the reader to the KR(2021), but I would be remiss in not also mentioning this closely related paper by Immorlica et. al. (2011). As an aside, there is an obvious connection between homogenization and algorithmic price fixing (see Greenwald and Kephart (1999)) that is a subject for a future post.
Next, I consider a feature absent in KR(2021), I think critical. Wages. To see their presence will make a difference in how we view algorithmic homogenization, suppose two firms competing for a worker. The worker’s type is their productivity, denoted 
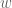

Irrespective of whether algorithmic homogenization will improve or decrease efficiency, we might still be worried about because of the possibility of systematic errors. In the meeting referenced earlier, Ashia Wilson asked her audience to imagine what might happen if a company like HireVue, for example, were to occupy a dominant position in the recruitment market (this would allow HireVue to effect wages, but that is a different story). HireVue and companies like it, claim that they provide accurate signals about a job candidates fit (there is a discussion to be had about whether this what they should be doing) with a given employer rapidly and at scale. Suppose the prediction algorithm that HireVue uses is indeed more accurate (in aggregate) than the alternative, but exhibits systematic errors for some well defined subset of job seekers. For example, it consistently underestimates the quality of fit for candidates whose last names have to many consonants (or over estimates this)? Depending on the nature of the alternative, this might be a concern. Does this call for an intervention or regulation? Why is it not in HireVue’s interest to discover such errors and correct them? If a company like Hirevue is rewarded per person placed, then, such a systematic error would lower their placement rate and thus their revenues.
I
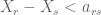 . Inequalities of this form arise in a variety of places. They can be interpreted as the dual to the problem of finding a shortest path in a network. Their feasibility is related to Rockafellar’s cyclic monotonicity condition. They arise in revealed preference and mechanism design. All the results one needs for the various applications appear in that paper.
. Inequalities of this form arise in a variety of places. They can be interpreted as the dual to the problem of finding a shortest path in a network. Their feasibility is related to Rockafellar’s cyclic monotonicity condition. They arise in revealed preference and mechanism design. All the results one needs for the various applications appear in that paper. be the set of possible states and
be the set of possible states and 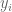 be the output in state
be the output in state 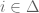 . Without loss we may assume that
. Without loss we may assume that  . An action for an agent is a pair
. An action for an agent is a pair 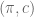 where
where 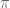 is a probability distribution over
is a probability distribution over  a cost. Denote by
a cost. Denote by 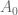 the set of known actions of which a typical element is written as
the set of known actions of which a typical element is written as 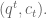
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) represents the share of output that goes to the agent. Actually, the requirement that
represents the share of output that goes to the agent. Actually, the requirement that 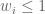 is not needed. The expected payoff to the agent under contract
is not needed. The expected payoff to the agent under contract 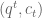 is
is 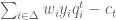 . Let
. Let 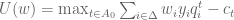 . Thus,
. Thus, 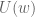 represents the agent’s expected payoff from choosing an action in
represents the agent’s expected payoff from choosing an action in 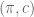 to offer the agent so as to minimize the principal’s payoff. Nature’s choice can be formulated as the following linear program:
to offer the agent so as to minimize the principal’s payoff. Nature’s choice can be formulated as the following linear program: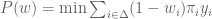
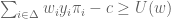
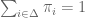
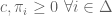
![\alpha \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) in each state of the world to the agent. Let
in each state of the world to the agent. Let 
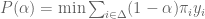
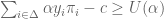
 is called admissible if
is called admissible if 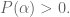
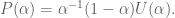
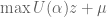
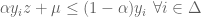
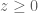
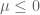 .
. must satisfy one of the following:
must satisfy one of the following:

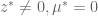
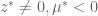
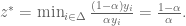
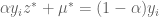
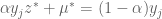
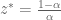 and therefore,
and therefore, 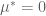 , which puts us back in #3. QED
, which puts us back in #3. QED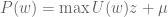
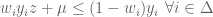
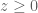
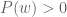 and
and 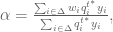 then,
then,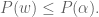
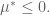
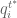 and add them up. This yields the following:
and add them up. This yields the following: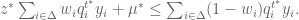
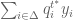 :
:![\alpha z^* + [\sum_{i \in \Delta}q_i^{t^*}y_i]^{-1}\mu^* \leq (1-\alpha)](https://s0.wp.com/latex.php?latex=%5Calpha+z%5E%2A+%2B+%5B%5Csum_%7Bi+%5Cin+%5CDelta%7Dq_i%5E%7Bt%5E%2A%7Dy_i%5D%5E%7B-1%7D%5Cmu%5E%2A+%5Cleq+%281-%5Calpha%29&bg=ffffff&fg=545454&s=0&c=20201002)
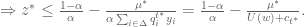
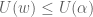 , it follows that
, it follows that![P(w) \leq [\frac{1-\alpha}{\alpha} - \frac{\mu^*}{U(w) + c_{t^*}}]U(w) + \mu^*](https://s0.wp.com/latex.php?latex=P%28w%29+%5Cleq+%5B%5Cfrac%7B1-%5Calpha%7D%7B%5Calpha%7D+-+%5Cfrac%7B%5Cmu%5E%2A%7D%7BU%28w%29+%2B+c_%7Bt%5E%2A%7D%7D%5DU%28w%29+%2B+%5Cmu%5E%2A&bg=ffffff&fg=545454&s=0&c=20201002)
 QED
QED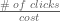 . Hence, the ROI is the inverse of the cost per click.
. Hence, the ROI is the inverse of the cost per click. . Then, my ROI target, says that the platform must deliver
. Then, my ROI target, says that the platform must deliver 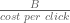 clicks. For example, at a budget of $100 and an ROI target of 2, I am telling the platform that I will give them $100 in return for 200 clicks. Now, the platform, has access not to a finite number of clicks but a flow. They can, given time, satisfy every bid. In short, the platform will get your $100. The only issue is when. The automated auction is merely an elaborate device for determining the rate at which different bidders receive a click. One can think of far simpler procedures to do this. For example, round robin or deplete budgets at a uniform rate.
clicks. For example, at a budget of $100 and an ROI target of 2, I am telling the platform that I will give them $100 in return for 200 clicks. Now, the platform, has access not to a finite number of clicks but a flow. They can, given time, satisfy every bid. In short, the platform will get your $100. The only issue is when. The automated auction is merely an elaborate device for determining the rate at which different bidders receive a click. One can think of far simpler procedures to do this. For example, round robin or deplete budgets at a uniform rate.
Recent Comments