A Bayesian agent is observing a sequence of outcomes in  . The agent does not know the outcomes in advance, so he forms some belief
. The agent does not know the outcomes in advance, so he forms some belief  over sequences of outcomes. Suppose that the agent believes that the number
over sequences of outcomes. Suppose that the agent believes that the number  of successes in
of successes in  consecutive outcomes is distributed uniformly in
consecutive outcomes is distributed uniformly in  and that all configuration with successes are equally likely:
and that all configuration with successes are equally likely:

for every  where
where  .
.
You have seen this belief already though maybe not in this form. It is a belief of an agent who tosses an i.i.d. coin and has some uncertainty over the parameter of the coin, given by a uniform distribution over ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
In this post I am gonna make a fuss about the fact that as time goes by the agent learns the parameter of the coin. The word `learning’ has several legitimate formalizations and today I am talking about the oldest and probably the most important one — consistency of posterior beliefs. My focus is somewhat different from that of textbooks because 1) As in the first paragraph, my starting point is the belief about outcome sequences, before there are any parameters and 2) I emphasize some aspects of consistency which are unsatisfactory in the sense that they don’t really capture our intuition about learning. Of course this is all part of the grand marketing campaign for my paper with Nabil, which uses a different notion of learning, so this discussion of consistency is a bit of a sidetrack. But I have already came across some VIP who i suspect was unaware of the distinction between different formulations of learning, and it wasn’t easy to treat his cocky blabbering in a respectful way. So it’s better to start with the basics.
Let  be a finite set of outcomes. Let
be a finite set of outcomes. Let  be a belief over the set
be a belief over the set  of infinite sequences of outcomes, also called realizations. A decomposition of is given by a set
of infinite sequences of outcomes, also called realizations. A decomposition of is given by a set  of parameters, a belief
of parameters, a belief  over , and, for every
over , and, for every  a belief
a belief 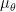 over such that
over such that  . The integral in the definition means that the agent can think about the process as a two stages randomization: First a parameter
. The integral in the definition means that the agent can think about the process as a two stages randomization: First a parameter  is drawn according to and then a realization
is drawn according to and then a realization  is drawn according to . Thus, a decomposition captures a certain way in which a Bayesian agent arranges his belief. Of course every belief admits many decompositions. The extreme decompositions are:
is drawn according to . Thus, a decomposition captures a certain way in which a Bayesian agent arranges his belief. Of course every belief admits many decompositions. The extreme decompositions are:
- The Trivial Decomposition. Take
 and
and  .
.
- Dirac’s Decomposition. Take
 and
and  . A “parameter” in this case is a measure
. A “parameter” in this case is a measure  that assigns probability 1 to the realization .
that assigns probability 1 to the realization .
Not all decompositions are equally exciting. We are looking for decompositions in which the parameter captures some `fundamental property’ of the process. The two extreme cases mentioned above are usually unsatisfactory in this sense. In Dirac’s decomposition, there are as many parameters as there are realizations; parameters simply copy realizations. In the trivial decomposition, there is a single parameter and thus cannot discriminate between different interesting properties. For stationary process, there is a natural decomposition in which the parameters distinguish between fundamental properties of the process. This is the ergodic decomposition, according to which the parameters are the ergodic beliefs. Recall that in this decomposition, a parameter captures the empirical distribution of blocks of outcomes in the infinite realization.
So what about learning ? While observing a process, a Bayesian agent will update his belief about the parameter. We denote by 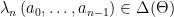 the posterior belief about the parameter at the beginning of period
the posterior belief about the parameter at the beginning of period  after observing the outcome sequence
after observing the outcome sequence  . The notion of learning I want to talk about in this post is that this belief converges to a belief that is concentrated on the true parameter . The example you should have in mind is the coin toss example I started with: while observing the outcomes of the coin the agent becomes more and more certain about the true parameter of the coin, which means his posterior belief becomes concentrated around a belief that gives probability
. The notion of learning I want to talk about in this post is that this belief converges to a belief that is concentrated on the true parameter . The example you should have in mind is the coin toss example I started with: while observing the outcomes of the coin the agent becomes more and more certain about the true parameter of the coin, which means his posterior belief becomes concentrated around a belief that gives probability  to the true parameter.
to the true parameter.
Definition 1 A decomposition of is consistent if for -almost every it holds that
![\displaystyle \lambda_n\left(a_0,\dots,a_{n-1}\right)\xrightarrow[n\rightarrow\infty]{w}\delta_\theta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clambda_n%5Cleft%28a_0%2C%5Cdots%2Ca_%7Bn-1%7D%5Cright%29%5Cxrightarrow%5Bn%5Crightarrow%5Cinfty%5D%7Bw%7D%5Cdelta_%5Ctheta&bg=ffffff&fg=000000&s=0&c=20201002)
for -almost every realization 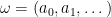 .
.
In this definition,  is Dirac atomic measure on and the convergence is weak convergence of probability measures. No big deal if you don’t know what it means since it is exactly what you expect.
is Dirac atomic measure on and the convergence is weak convergence of probability measures. No big deal if you don’t know what it means since it is exactly what you expect.
So, we have a notion of learning, and a seminal theorem of L.J. Doob (more on that below) implies that the ergodic decomposition of every stationary process is consistent. While this is not something that you will read in most textbooks (more on that below too), it is still well known. Why do Nabil and I dig further into the issue of learnability of the ergodic decomposition ? Two reasons. First, one has to write papers. Second, there is something unsatisfactory about the concept of consistency as a formalization of learning. To see why, consider the belief that outcomes are i.i.d. with probability  for success. This belief is ergodic, so from the perspective of the ergodic decomposition the agent `knows the process’ and there is nothing else to learn. But let’s look at Dirac’s decomposition instead of the ergodic decomposition. Then the parameter space equals the space of all realizations. Suppose the true parameter (=realization) is
for success. This belief is ergodic, so from the perspective of the ergodic decomposition the agent `knows the process’ and there is nothing else to learn. But let’s look at Dirac’s decomposition instead of the ergodic decomposition. Then the parameter space equals the space of all realizations. Suppose the true parameter (=realization) is 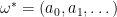 , then after observing the first outcomes of the process the agent’s posterior belief about the parameter is concentrated on all that agrees with
, then after observing the first outcomes of the process the agent’s posterior belief about the parameter is concentrated on all that agrees with  on the first coordinates. These posterior beliefs converge to
on the first coordinates. These posterior beliefs converge to  , so that Dirac decomposition is also consistent ! We may say that we learn the parameter, but “learning the parameter” in this environment is just recording the past. The agent does not gain any new insight about the future of the process from learning the parameter.
, so that Dirac decomposition is also consistent ! We may say that we learn the parameter, but “learning the parameter” in this environment is just recording the past. The agent does not gain any new insight about the future of the process from learning the parameter.
In my next post I will talk about other notions of learning, originating in a seminal paper of Blackwell and Dubins, which capture the idea that an agent who learns a parameter can make predictions as if he new the parameter. Let me also say here that this post and the following ones are much influenced by a paper of Jackson, Kalai, Smorodinsky. I will talk more on that paper in another post.
For the rest of this post I am going to make some comments about Bayesian consistency which, though again standard, I don’t usually see them in textbooks. Especially I don’t know of a reference for the version of Doob’s Theorem which I give below, so if any reader can give me such a reference it will be helpful.
First, you may wonder whether every decomposition is consistent. The answer is no. For a trivial example, take a situation where are the same for every . More generally troubles arrise when the realization does not pin down the parameter. Formally, let us say that function  pins down or identifies the parameter if
pins down or identifies the parameter if
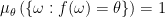
for -almost every . If such  exists then the decomposition is identifiable.
exists then the decomposition is identifiable.
We have the following
Theorem 2 (Doob’s Theorem) A decomposition is identifiable if and only if it is consistent.
The `if’ part follows immediately from the definitions. The `only if’ part is deep, but not difficult: it follows immediately from the martingale convergence theorem. Indeed, Doob’s Theorem is usually cited as the first application of martingales theory.
Statisticians rarely work with this abstract formulation of decomposition which I use. For this reason, the theorem is usually formulated only for the case that  and is i.i.d. . In this case the fact that the decomposition is identifiable follows from the strong law of large numbers. Doob’s Theorem then implies the standard consistency of Bayesian estimator of the parameter .
and is i.i.d. . In this case the fact that the decomposition is identifiable follows from the strong law of large numbers. Doob’s Theorem then implies the standard consistency of Bayesian estimator of the parameter .


4 comments
August 10, 2014 at 7:43 am
normaldeviate
We statisticians would prefer to define consistency to mean
that the posterior converges to a point mass with respect
to the data generating distribution, not the Bayesian’s own
marginal distribution (as in Doob’s result). The latter is solopsistic.
If you do it w.r.t. the data generating process, you find that the
set of consistent pairs (data generating processes, priors) that
lead to consistency is a topological null set.
See my old blog post:
Best wishes
Larry Wasserman
August 10, 2014 at 9:09 am
Eran
Yea I abused the standard terminology slightly. I thought I could get away with it because I define `consistency of decomposition’ while consistency is usually defined for a pair (lambda,theta)
Btw, this theorem of Freedman needs infinite set of outcomes. I use finite set of outcomes. On the other hand I work in a stationary environment while statisticians assume that the parameter corresponds to an i.i.d. distribution. I believe Freedman’s argument with minor changes also applies to my setup: for a co-meager set of pairs of a parameter (=ergodic distribution) theta and a belief lambda over parameter the Bayesian estimator that is calculated with lambda will not converge to theta.
Btw II. I like Freedman’s Theorem, but I think it is relevant only if you are not a religiously committed Bayesian. To care about a negligible set of parameters you need to be somebody who only uses Bayesian estimator as a tool, but does not really believe in the prior over parameters.
Thanks !
August 10, 2014 at 10:32 am
normaldeviate
agreed
August 11, 2014 at 8:41 am
Jim
Very interesting. My Bayes is quite rusty, but I think I follow the main argument. I have a language case in mind, particularly Gold ’68, where without negative evidence (corrections) the language learner will never converge on the language within the limit. In language acquisition, there’s a well documented lack of corrections in a child’s input stream. This is the notoriously thorny problem known as the “Poverty of Stimulus Argument.”
However, if a Bayesian learner (in this case language learner) can make predictions on parameters using a Dirac Decomposition, and that Dirac Decomposition is consistent, then perhaps (possibly), the learner can make inferences about the structure of the language and perhaps (possibly) generate negative evidence when an input or output violates the Dirac Decomposition Consistency.
I’m rusty and shooting from the hip here, but that’s what stood out for me.