Here is the question from Ross’ book that I posted last week
Question 1 We have two coins, a red one and a green one. When flipped, one lands heads with probability 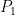 and the other with probability
and the other with probability 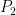 . Assume that
. Assume that  . We do not know which coin is the coin. We initially attach probability
. We do not know which coin is the coin. We initially attach probability  to the red coin being the coin. We receive one dollar for each heads and our objective is to maximize the total expected discounted return with discount factor
to the red coin being the coin. We receive one dollar for each heads and our objective is to maximize the total expected discounted return with discount factor  . Find the optimal policy.
. Find the optimal policy.
This is a dynamic programming problem where the state is the belief that the red coin is . Every period we choose a coin to toss, get a reward and updated our state given the outcome. Before I give my solution let me explain why we can’t immediately invoke uncle Gittins.
In the classical bandit problem there are  arms and each arm
arms and each arm  provides a reward from an unknown distribution
provides a reward from an unknown distribution ![{\theta_i\in\Delta([0,1])}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta_i%5Cin%5CDelta%28%5B0%2C1%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Bandit problems are used to model tradeoffs between exploitation and exploration: Every period we either exploit an arm about whose distribution we already have a good idea or explore another arm. The
. Bandit problems are used to model tradeoffs between exploitation and exploration: Every period we either exploit an arm about whose distribution we already have a good idea or explore another arm. The 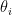 are randomized independently according to distributions
are randomized independently according to distributions ![{\mu_i\in \Delta(\Delta([0,1]))}](https://s0.wp.com/latex.php?latex=%7B%5Cmu_i%5Cin+%5CDelta%28%5CDelta%28%5B0%2C1%5D%29%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and what we are interested in is the expected discounted reward. The optimization problem has a remarkable solution: choose in every period the arm with the largest Gittins index. Then update your belief about that arm using Bayes’ rule. The Gittins index is a function which attaches a number
, and what we are interested in is the expected discounted reward. The optimization problem has a remarkable solution: choose in every period the arm with the largest Gittins index. Then update your belief about that arm using Bayes’ rule. The Gittins index is a function which attaches a number  (the index) to every belief
(the index) to every belief  about an arm. What is important is that the index of an arm depends only on
about an arm. What is important is that the index of an arm depends only on  — our current belief about the distribution of the arm — not on our beliefs about the distribution of the other arms.
— our current belief about the distribution of the arm — not on our beliefs about the distribution of the other arms.
The independence assumption means that we only learn about the distribution of the arm we are using. This assumption is not satisfied in the red coin green coin problem: If we toss the red coin and get heads then the probability that the green coin is decreases. Googling `multi-armed bandit’ with `dependent arms’ I got some papers which I haven’t looked at carefully but my superficial impression is that they would not help here.
Here is my solution. Call the problem I started with `the difficult problem’ and consider a variant which I call `the easy problem’. Let 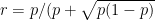 so that
so that  . In the easy problem there are again two coins but this time the red coin is with probability
. In the easy problem there are again two coins but this time the red coin is with probability  and with probability
and with probability  and, independently, the green coin is with probability
and, independently, the green coin is with probability  and with probability . The easy problem is easy because it is a bandit problem. We have to keep track of beliefs
and with probability . The easy problem is easy because it is a bandit problem. We have to keep track of beliefs 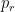 and
and 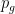 about the red coin and the green coin ( is the probability that the red coin is ), starting with
about the red coin and the green coin ( is the probability that the red coin is ), starting with 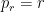 and
and 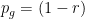 , and when we toss the red coin we update but keep fixed. It is easy to see that the Gittins index of an arm is a monotone function of the belief that the arm is so the optimal strategy is to play red when
, and when we toss the red coin we update but keep fixed. It is easy to see that the Gittins index of an arm is a monotone function of the belief that the arm is so the optimal strategy is to play red when 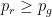 and green when
and green when  . In particular, the optimal action in the first period is red when
. In particular, the optimal action in the first period is red when 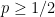 and green when
and green when 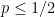 .
.
Now here comes the trick. Consider a general strategy  that assigns to every finite sequence of past actions and outcomes an action (red or green). Denote by
that assigns to every finite sequence of past actions and outcomes an action (red or green). Denote by  and
and  the rewards that gives in the difficult and easy problems respectively. I claim that
the rewards that gives in the difficult and easy problems respectively. I claim that
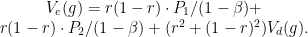
Why is that ? in the easy problem there is a probability  that both coins are . If this happens then every gives payoff
that both coins are . If this happens then every gives payoff 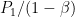 . There is a probability that both coins are . If this happens then every gives payoff
. There is a probability that both coins are . If this happens then every gives payoff  . And there is a probability
. And there is a probability  that the coins are different, and, because of the choice of , conditionally on this event the probability of
that the coins are different, and, because of the choice of , conditionally on this event the probability of  being is . Therefore, in this case gives whatever gives in the difficult problem.
being is . Therefore, in this case gives whatever gives in the difficult problem.
So, the payoff in the easy problem is a linear function of the payoff in the difficult problem. Therefore the optimal strategy in the difficult problem is the same as the optimal strategy in the easy problem. In particular, we just proved that, for every , the optimal action in the first period is red when and green with . Now back to the dynamic programming formulation, from standard arguments it follows that the optimal strategy is to keep doing it forever, i.e., at every period to toss the coin that is more likely to be the coin given the current information.
See why I said my solution is tricky and specific ? it relies on the fact that there are only two arms (the fact that the arms are coins is not important). Here is a problem whose solution I don’t know:
Question 2 Let  . We are given coins, one of each parameter, all
. We are given coins, one of each parameter, all  possibilities equally likely. Each period we have to toss a coin and we get payoff
possibilities equally likely. Each period we have to toss a coin and we get payoff  for Heads. What is the optimal strategy ?
for Heads. What is the optimal strategy ?


1 comment
November 10, 2014 at 6:46 am
Anonymous
hope this showed up in the search. still only 2 arms though.
‘Good news and bad news in two-armed bandits’ Journal of Economic Theory, Volume 135, Issue 1, July 2007, Pages 558–566